Automating mixed-reality environment capture
Summary: Mixed Reality on Quest needed reliable 3D maps of users’ rooms, but capture tech and requirements were immature. I led the design of the capture model, aligned teams on what data we needed, explored feasible UX patterns, and defined a three-step capture flow that set the foundation for future automated room scanning.
The Challenge
Mixed Reality only works if the headset can build a watertight, accurate 3D model of a user’s room. Early Quest devices relied on a manual, low-fidelity setup flow that wasn’t designed to support MR physics, occlusion, or object interactions.
Meta needed a path toward automated room scanning, but the organization lacked clarity on three fronts:
- Detection technology was still immature and unreliable.
- Teams held conflicting assumptions about what “capture” should produce.
- No one had defined the system requirements or workflow needed to support MR at platform scale.
My role was to establish a unified model for environment capture and align design, PM, and engineering on a viable approach that could evolve from manual labeling → assisted capture → future automated scanning.
Defining What Capture Must Produce
I led cross-functional workshops with SLAM engineers, perception researchers, MR experience teams, and external developers to clarify what the capture system needed to output—independent of UI or technical preferences.
Through synthesis of MR use cases and tech constraints, we defined capture requirements:
- A watertight room volume to support physics and boundaries.
- Detectable planes (walls, floors, ceilings).
- Object volumes and categories for interaction models.
- Optional high-fidelity meshes for advanced experiences.
This became the first shared, platform-level definition of what “capture” needed to produce, shifting conversations away from feature debates toward functional MR requirements.

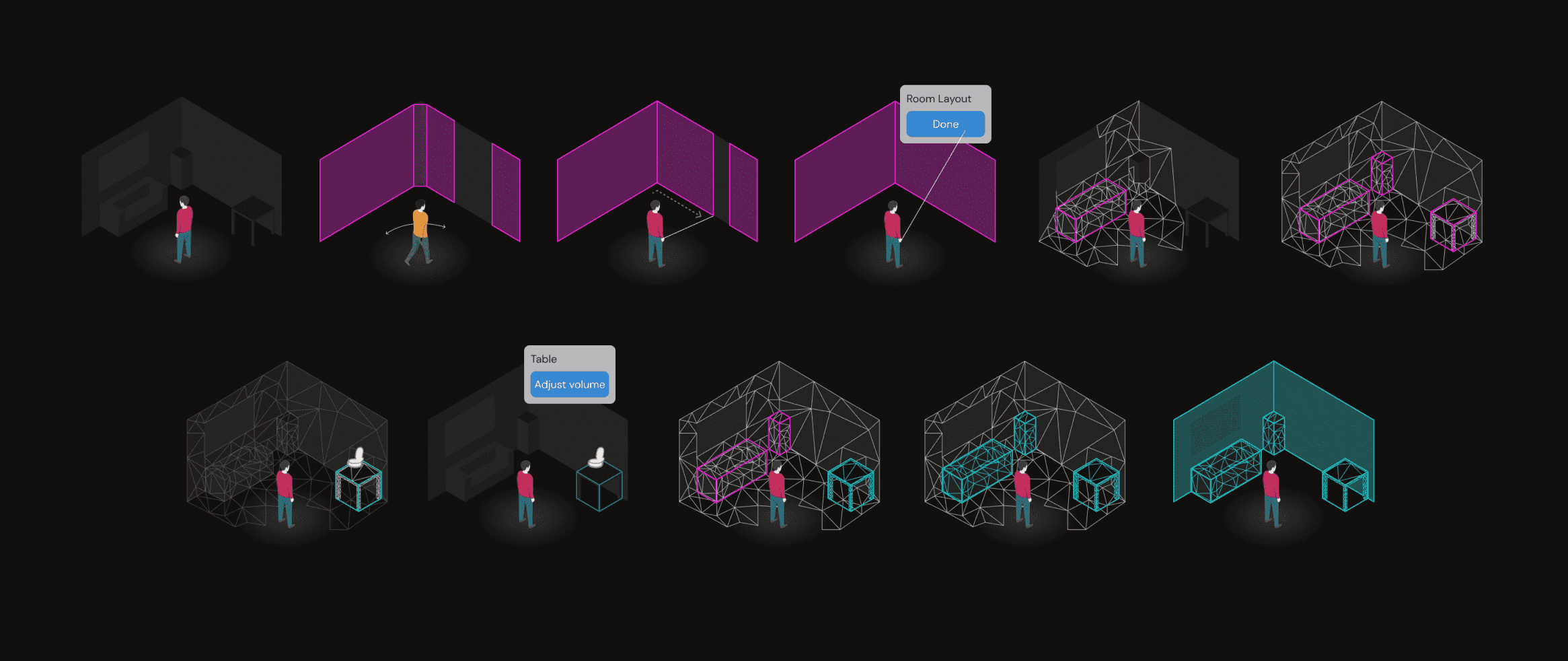
Exploring the solution space
With requirements set, I mapped a spectrum of viable UX approaches—balancing user expectations with early technical constraints.
- Room → guided objects: Most reliable, higher user effort.
- Room → automatic object detection: Better UX, moderate tech risk.
- Room + objects simultaneously: Long-term ideal, not yet feasible.
Each model was evaluated for detection feasibility, error-recovery patterns, clarity of user mental model, engineering cost, and its pathway toward future automation. This produced the first strategic roadmap for how capture could evolve over multiple hardware cycles.
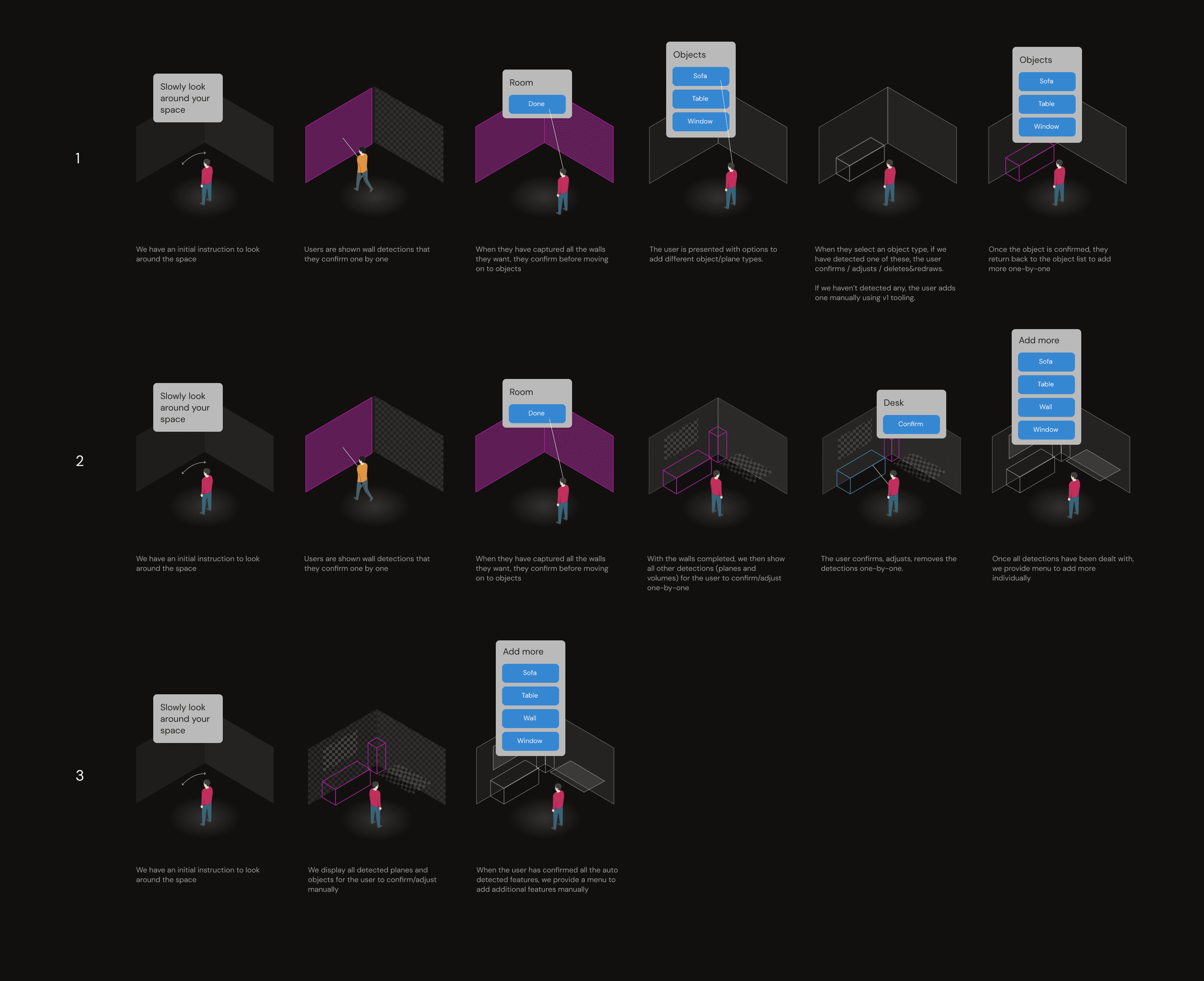
Designing for Imperfect Technology
Because perception systems were still developing, the UX needed robust fallback paths for real-world failures, including:
- Successful detection.
- Partial or incorrect detection.
- Complete failure to detect surfaces.
- Open-plan spaces with no natural boundaries.
I designed flows that allowed users to correct errors, add missing geometry, and maintain a coherent room model even when automation struggled—ensuring predictable MR behavior despite tech limitations.
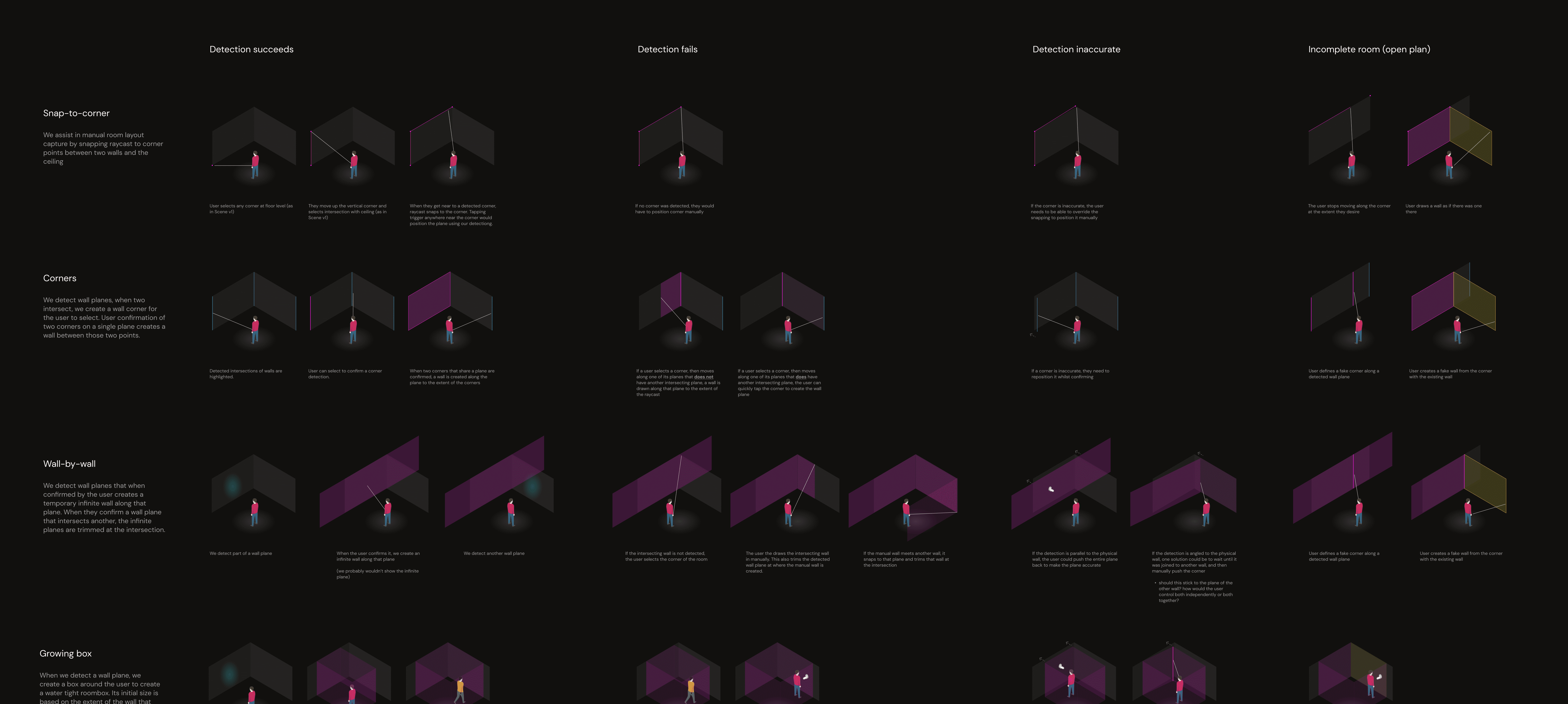
Prototyping Ahead of the Tech
Because the underlying detection system was still in development, we couldn’t rely on functional prototypes to validate our UX. To unblock progress, I partnered with a small engineering team to define and build a fake-data prototyping environment that simulated detection accuracy and errors based on current predictions.
This allowed us to run realistic UX tests, compare flows, and make confident recommendations before the core tech was fully available.
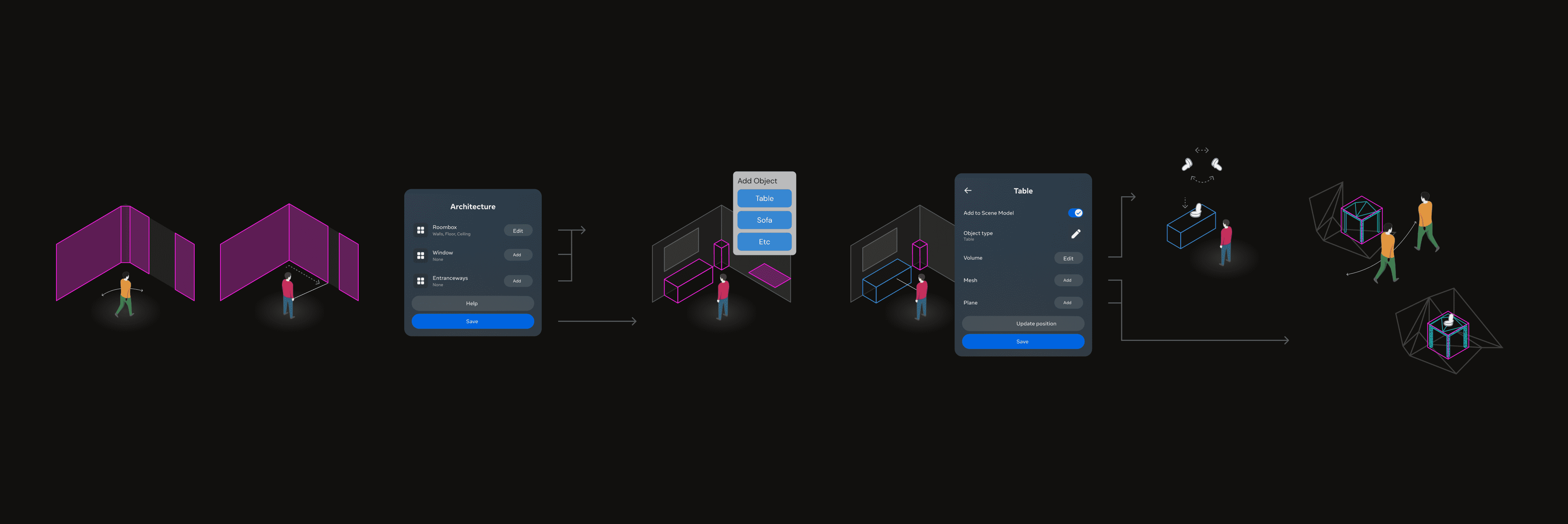
Final Direction: A Three-Step Capture Model
Through structured trade-off reviews with engineering and product leadership, we aligned on a launchable sequence that balanced usability, clarity, and technical feasibility:
- Capture the room: Establish watertight bounds and correct inaccuracies.
- Detect planes and object volumes: Automate surfaces and major objects.
- Optional mesh refinement: Add fidelity where experiences require it.
This framework created a scalable path toward fully automated capture while ensuring the initial experience was stable, recoverable, and intuitive.

Impact
This project laid the conceptual and structural foundations for Meta’s modern environment-capture pipeline.
After I left, the core principles defined here—room → planes → objects, with optional mesh refinement—were adopted into the Meta Spatial Scanner, the official reference implementation used across Quest devices. It now appears in Meta’s developer documentation: Spatial Scanner Overview.
The same model underpins the scanning capabilities demonstrated in the Meta Connect 2025 Developer Keynote, where Meta showcased room scanning, mesh reconstruction, and spatial understanding built on top of these foundations.
This work provided:
- The first unified definition of capture requirements used by XR, SLAM, and SDK teams.
- A stable spatial data model that unblocked MR experience development across the Quest ecosystem.
- A scalable architectural path from manual capture to assisted workflows to future full automation.
- Prototype environments and decision frameworks still referenced in today’s Spatial SDK evolution.
In short, this project transformed capture from an experimental feature into a platform-level capability now embedded in Quest devices, the Spatial SDK, and the developer tooling ecosystem.